 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Features for Context-Aware Speech Recognition
Dec 01, 2017
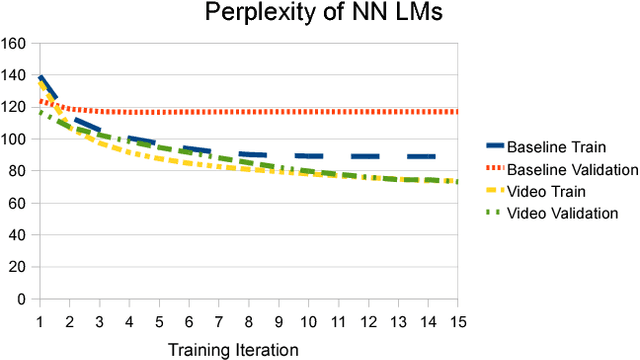

Automatic transcriptions of consumer-generated multi-media content such as "Youtube" videos still exhibit high word error rates. Such data typically occupies a very broad domain, has been recorded in challenging conditions, with cheap hardware and a focus on the visual modality, and may have been post-processed or edited. In this paper, we extend our earlier work on adapting the acoustic model of a DNN-based speech recognition system to an RNN language model and show how both can be adapted to the objects and scenes that can be automatically detected in the video. We are working on a corpus of "how-to" videos from the web, and the idea is that an object that can be seen ("car"), or a scene that is being detected ("kitchen") can be used to condition both models on the "context" of the recording, thereby reducing perplexity and improving transcription. We achieve good improvements in both cases and compare and analyze the respective reductions in word error rate. We expect that our results can be used for any type of speech processing in which "context" information is available, for example in robotics, man-machine interaction, or when indexing large audio-visual archives, and should ultimately help to bring together the "video-to-text" and "speech-to-text" communities.
* 5 pages and 3 figures
EESEN: End-to-End Speech Recognition using Deep RNN Models and WFST-based Decoding
Oct 18, 2015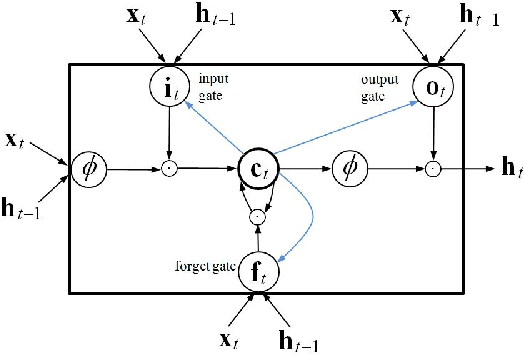


The performance of automatic speech recognition (ASR) has improved tremendously due to the application of deep neural networks (DNNs). Despite this progress, building a new ASR system remains a challenging task, requiring various resources, multiple training stages and significant expertise. This paper presents our Eesen framework which drastically simplifies the existing pipeline to build state-of-the-art ASR systems. Acoustic modeling in Eesen involves learning a single recurrent neural network (RNN) predicting context-independent targets (phonemes or characters). To remove the need for pre-generated frame labels, we adopt the connectionist temporal classification (CTC) objective function to infer the alignments between speech and label sequences. A distinctive feature of Eesen is a generalized decoding approach based on weighted finite-state transducers (WFSTs), which enables the efficient incorporation of lexicons and language models into CTC decoding. Experiments show that compared with the standard hybrid DNN systems, Eesen achieves comparable word error rates (WERs), while at the same time speeding up decoding significantly.
Kaldi+PDNN: Building DNN-based ASR Systems with Kaldi and PDNN
Jan 27, 2014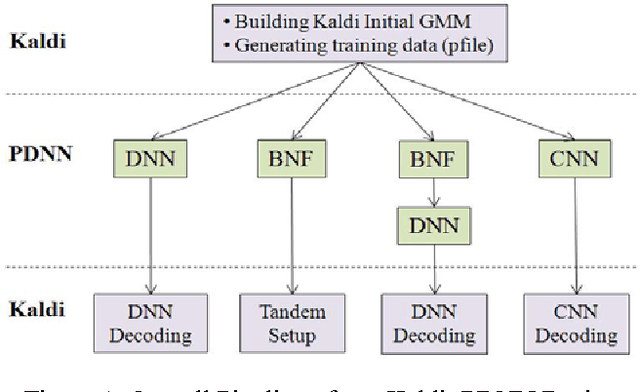

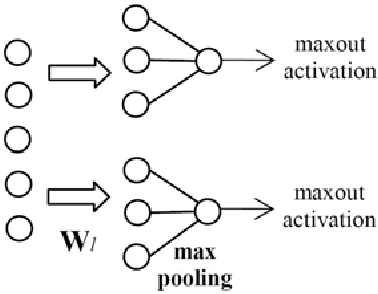
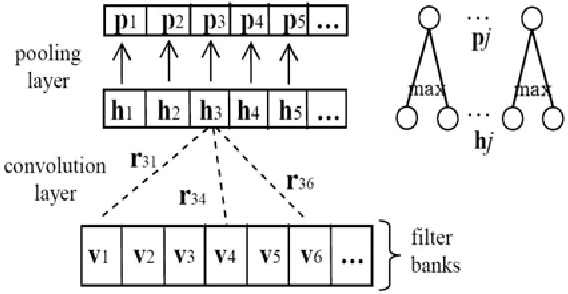
The Kaldi toolkit is becoming popular for constructing automated speech recognition (ASR) systems. Meanwhile, in recent years, deep neural networks (DNNs) have shown state-of-the-art performance on various ASR tasks. This document describes our open-source recipes to implement fully-fledged DNN acoustic modeling using Kaldi and PDNN. PDNN is a lightweight deep learning toolkit developed under the Theano environment. Using these recipes, we can build up multiple systems including DNN hybrid systems, convolutional neural network (CNN) systems and bottleneck feature systems. These recipes are directly based on the Kaldi Switchboard 110-hour setup. However, adapting them to new datasets is easy to achieve.